In nearly every sector, companies are overhauling their data infrastructure to meet emerging industry, regulatory, and customer demands. In the financial services industry, banks, asset managers, brokerages, and hedge funds are all engaging in strategic transformation initiatives designed to enhance their ability to consume available information, synthesize insights, and improve decision making.
Read the E-Book Here
The insurance industry is no exception to this trend. As evidenced by the rise of terms like “Insurtech”, these companies are maturing digitally to extend traditional business lines and innovate on new opportunities. However, much of this focus is applied to the insurance, or liability side, of the insurance business. Phone apps, modern policy structures, and competitive pricing are consumer-facing innovations based on technology and data aimed at driving increased policy revenues through better client segmentation and sales channel diversification.
Just as important for an insurance company, if not more so, is the investment management side of the business. The core of the entire insurance business model rests on the ability of these companies to deploy capital in a manner that captures a yield spread above projected liabilities. Yet, this side of the business is still plagued with many data and technology challenges that inhibit the accurate, timely, and complete flow of information to Chief Investment Officers and their teams. As a result, firms struggle to make optimized and informed investment decisions.
Improved information, industry-wide, has the potential to alter the way in which a significant amount of assets is invested. These assets are tied to future liabilities. Improved investment decisions, fueled by data best practices, can increase the yield on this capital, widening spreads over liabilities, thereby strengthening the capital position of these insurance companies. This also has the potential to increase the ability of these companies to compete on price, delivering economic benefits back to customers.
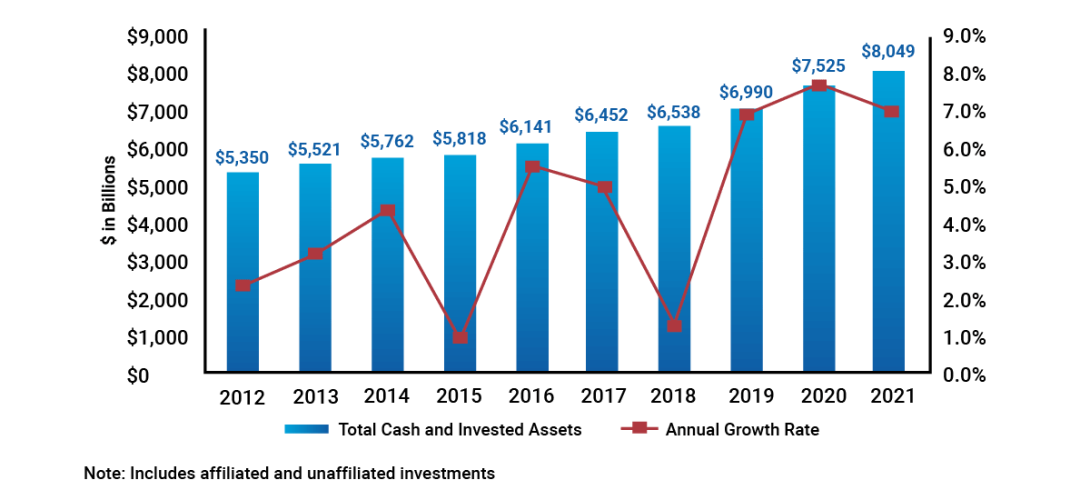
Chart 1: Historican U.S. Insurance Industry Total Cash and Invested Assets, Year-End 2012-2021
Source: https://content.naic.org/sites/default/files/capital-markets-special-reports-asset-mix-ye2021.pdf
This article will explore five of the challenges that insurance companies face in relation to their investment data and offer thoughts on possible solution designs to overcome them.
5 Investment Data Challenges for Insurers
Challenge #1: Understanding Specific Data Rules for IBOR/ABOR
Integration of the firm’s Investment Book of Record (IBOR) with its Accounting Book of Record (ABOR) is consistently one of the most complex and important data management challenges for insurance investment organizations. Properly unified information from each of these systems is critical to investment decision-making by front-office personnel.
IBOR and ABOR systems occupy their own space within the insurer’s technology stack and cater to different user groups with differentiated needs, knowledge, and skill sets. IBOR systems provide portfolio managers with a robust security master enriched with market data, security analytics, risk calculations, compliance, and trading optimization tools. ABOR systems emphasize tax lot calculations like book values, accretion and gains/losses. Depending on each specific system’s capabilities, insurance companies also need to make considerations for regulatory reporting, NAIC ratings, capital charges, and agency reporting, which requires an integration of ABOR and IBOR data.
Integration of these data sets is a common obstacle for insurance companies given the varying levels of granularity and lack of a one-to-one relationship across data sources. Many-to-one and one-to-many data relationships require specific methodologies to perform averages, weighted averages, and other aggregation calculations. Standard aggregation methodologies are not well defined across the industry; therefore, firms must create their policies and programmatically automate the calculations to ensure the policies are adopted at an enterprise level within the organization.
In cases where both systems do exhibit matched granularity, there is still a challenge to appropriately map tax lots between systems. This is just as much a workflow and process consideration as it is a technology issue. Proper procedures must be enacted, governed, and followed to ensure that required data is entered into respective systems at each stage of the trade lifecycle, and that data flows appropriately and consistently between systems.
Solution:
There are many options to address these considerations depending on the resources available to the organization. The crux of the discussion typically revolves around the need for business logic, how that should be constructed and maintained, and where it should be deployed into a larger data pipeline. In general, the preferred method should be an option that centralizes all the necessary logic to a single location that has access to all the necessary data inputs. In many organizations, this takes the form of a data warehouse. This has the benefit of codifying centralized logic into data structures, archival of all inputs and outputs, robust auditing, and support to downstream processes to deliver files or populate reports.
Other options that could include the encapsulation of business logic into the reporting layer, desktop tools, or any manual task are sub-optimal in almost any scenario.
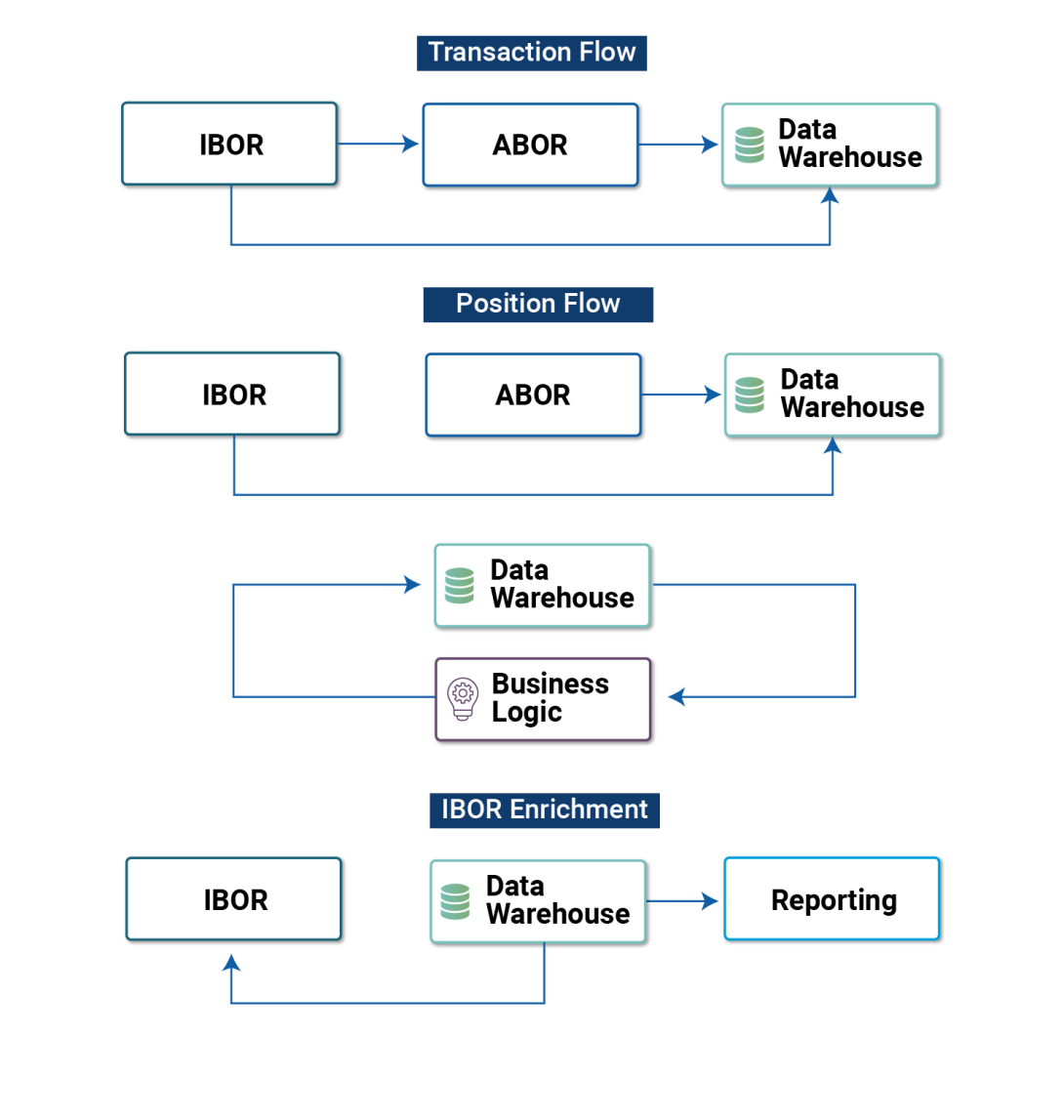
Chart 2: Data Flows
Diagram: Simplified investment data flows, exhibiting the differentiation of data sets, the need for a “hub”, in this case, a data warehouse, and the requirement to further disseminate that data downstream.
One key capability provided by the centralization of business logic to a holistic data warehouse is that data source hierarchies must be robustly maintained. ABOR and IBOR have broad sets of data unique to each system, but there is considerable overlap between the two as well. Given there are data fields that may exist in both systems, it is imperative to have a mechanism to dictate the preferred source, secondary, tertiary, and subordinate sources for each data element. Records that are cleansed and processed in this manner are typically referred to as “gold copy” data.
In insurance portfolios, where accounting drives much of the investment process, ABOR is likely to be the primary source for most inputs covered by the system, while IBOR would be the primary source for the rest. In a consolidated dataset from these two sources, a single data element could have lineage back to either system. When users work with this data, they should understand the provenance of these outputs, elevating the need for reporting metadata alongside any report data set.
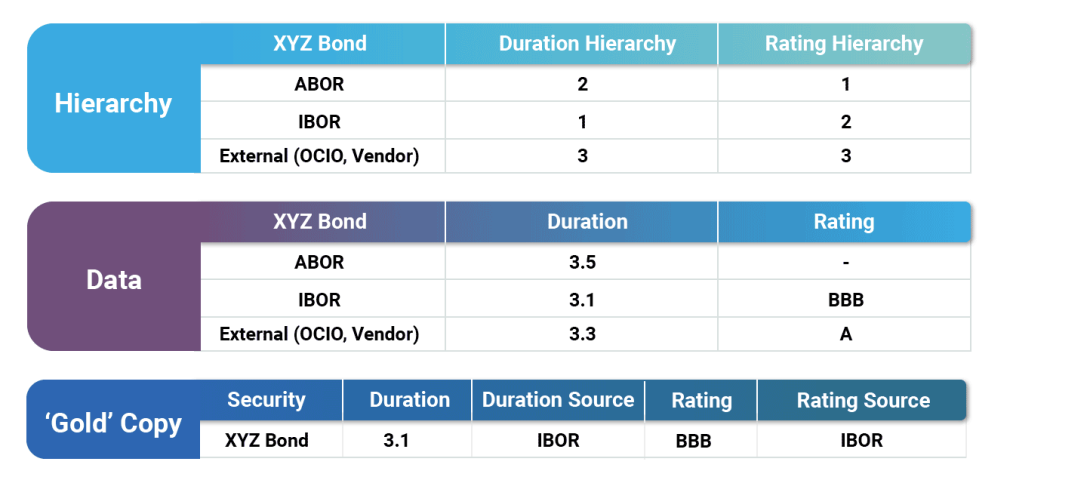
Chart 3: Data Source Hierarchy
Example: This example shows how a data source hierarchy can be established for any field (e.g. Duration and Rating), with the hierarchy value indicating the order of evaluation.
The primary source for Duration is IBOR, and it has provided a value, so it gets chosen. ABOR is the primary choice for Rating, but the value is not available, so the logic moves to the second choice, which is IBOR.
The source of the data values can change over time depending on the availability of data. It is critical to report the metadata explaining the lineage of each field, as illustrated in the third table.
Challenge #2: Using Outside External Managers
Another area that may complicate the ecosystem for insurance investment data is the use of external managers for targeted sleeves or asset classes within the portfolio. Outsourcing asset management to external managers does not eliminate the data requirements for those assets. In fact, new workflows will need to be developed to integrate data sets arriving from those external managers into the in-house systems of the insurer.
Each of these external managers will have their own respective IBOR and ABOR systems supported by internal workflows and policies. Data extracted from those systems will be provided in unique formats and often at inconvenient times relative to the daily processing of an internally managed book. Furthermore, insurers often have many external managers, significantly increasing the number of inbound data sources, and further amplifying the challenge to create a single version of the truth.
Solution:
Rarely will a singular IBOR or ABOR system be prepared to deal with the confluence of all these data sets. Oftentimes, the dynamics in this scenario require a centralized master hub that cleans, standardizes, and unifies the data to provide an enterprise perspective prior to distribution to downstream systems and data consumers. Lack of an enterprise view leads to data quality issues, inconsistent reporting, and ultimately legal and regulatory risk.
This is another case where overlapping data elements of multiple systems may require hierarchical approaches to define the “golden copy”. The same security may be held in both an externally and internally managed portfolio, potentially producing conflicting security setup information. Since the security terms and conditions should be viewed consistently across all held portfolios, a robust data source hierarchy with master record management and data translation capabilities is needed to derive a single version of the truth for each data domain including portfolios, securities, positions, transactions, and other ABOR/IBOR specific data elements.
Chart 4: Daily Interfaces

Diagram: The data hub’s responsibility is to handle both the variety of file formats and the resolution of their contents, upstream of the insurer’s primary investment systems, ensuring that the data is transformed into a context more aligned with the insurer's view of the world.
Challenge #3: Alternative Investment Systems
Throughout their history, insurance portfolios have been heavily weighted to investment-grade bonds, municipals, treasuries, and other low-risk fixed-income instruments. The yield from these asset classes provided enough spread over the insurance liabilities to support the business lines.
The low-rate environment of the past decade-plus renders this approach less effective without also dramatically raising policy premiums. In a world where these companies often compete on price, this approach may alienate consumers. Instead, insurance portfolios shifted their asset allocation to include riskier investments such as equities, structured products, private debt, and alternatives. These asset classes play a key role in boosting yield and portfolio returns; however, they also create additional data complexities that must be considered.
The complexity of these esoteric investments often demands standalone investment systems dedicated to managing non-traditional asset classes. These systems will sit upstream or alongside the primary IBOR and ABOR systems and create yet another integration challenge. This challenge has become so common that it has triggered consolidation among fintech providers attempting to deliver complete front-to-back, multi-asset solutions. Unless a portfolio system can seamlessly integrate the considerations of alternative investments into a holistic portfolio view and a common workflow, portfolio professionals are left to find workarounds.
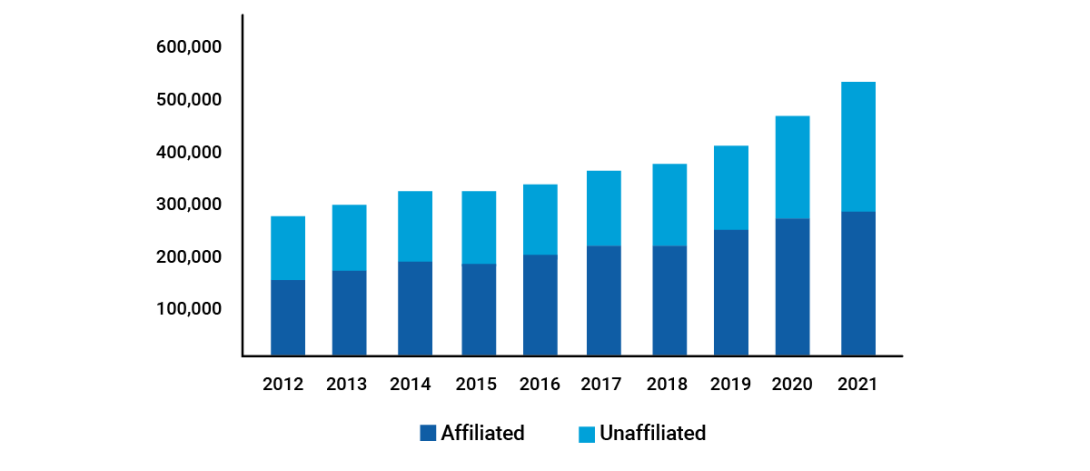
Chart 5: Historical U.S. Insurance Industry Schedule BA Exposure, 2012-2021 (BACV $ in millions)
Source: https://content.naic.org/sites/default/files/capital-markets-special-reports-Sch-BA-YE2021.pdf
Example: Using Schedule BA as a measure of non-traditional assets in insurance portfolios shows that the rise has been dramatic over the past decade.
Solution:
To prevent analytical gaps in their portfolio view, insurance companies must supply additional information for private investments not covered by standard data vendors. In many cases, the estimation of funding dates and approximation of incoming cash flows is key to integrating these assets into wider portfolio analytics. Cash flow projections are most likely done in a model outside of the IBOR system. These cash flows must find their way back to IBOR for inclusion in analytics, risk and cash calculations. In addition to accepting those off-system cash flows, the chosen IBOR security template must also comply with the insurer’s view of the investment’s risk profile. If using a factor model, care should be taken to ensure that the factors loaded to that security are appropriate when running any regression-based metrics.
Insurers must establish defined workflows for the setup and maintenance of these securities, complete with data quality monitoring and regular review. Most importantly, it is critical to establish clear lines of ownership and communication from the front office, risk team, and the proper operations personnel to support this task.
Challenge #4: Asset Liability Matching
Challenges also arise for insurance investments in integrating the portfolio data with other business metrics. In insurance, actuarial teams forecast the future liabilities of the insurance carrier. Investments must be made in a manner such that projected future cash flows provide a spread over these forecasted liabilities. These two sets of cash flow assumptions are foundational to the insurance business model and are key to the success of an insurance company.
However, these two data sets represent quite separate worlds. Actuarial forecasts often arrive in batches at the end of reporting periods from teams largely disconnected from the daily investment process. Those same teams are often responsible for matching up those liability streams with the projected asset cash flows, which may not be sourced in a manner consistent with the investment team’s updated assumptions. This results in a mismatch between the cash flow assumptions used by the investment team and those used by the actuarial team. This misalignment can materially skew and impact all forward-looking projections, pricing, and budgeting for the business.
Solution:
This can be corrected. There should be efforts made to align all modeling assumptions across the organization. This can be done by filtering all that data through the IBOR system. Cases may develop where the IBOR has analytics gaps for specific asset classes, and those may flow from other systems. But overall, these should be routed through IBOR wherever possible, providing a singular hub of this data, available to portfolio managers, and flowing downstream to actuarial teams. The result will be a single library of security cash flows, accessible to all groups, and updated in real-time through governed business processes and workflows.
Challenge #5: Compliance Validation
Financial services, in general, is one of the most highly regulated industries in the world, with insurance companies being held to a host of esoteric laws and controls specific to their line of business. Not only do insurance companies face regulatory scrutiny at the federal level, but they also are held to jurisdictional requirements within every operating region. In the U.S., this translates to specific state-level regulations for each state that the company may be operating.
In addition to the data management considerations for the variety of regulatory constraints that they face, insurance companies are also held to strict audit reviews where evidence of historical compliance must be produced. There are steps that these companies can take to better prepare themselves for audit reviews, saving time and money, while increasing transparency, consistency, and accuracy of the resulting data.
Solution:
There are at least three paths that insurance investment and technology teams should explore to facilitate more robust compliance reporting:
- Capture compliance test results at each step in the trade lifecycle: Data capture is paramount and should be integrated into every phase of the trading lifecycle. At any point in time when a compliance test can be triggered, the results of that test should be systemically logged to a database and available for compliance managers to review in real time.
- Record passing and failing compliance test results: Most compliance testing is exception-based, whereby only the violations or breaches are tracked and routed back to the traders and portfolio managers. This is common in many portfolio management systems and is suitable for flagging events that require corrective action. However, it does not create an audit trail tracking the fact that compliance was indeed evaluated along with a positive affirmation that no breach occurred. In producing audit documentation for specific trades, an organization most likely can only confirm that it passed compliance testing by the absence of a breach. Tracking both positive and negative affirmations is a best practice that supports a comprehensive audit trail for both internal and external purposes.
- Promote consistent, accurate data with data governance: Data governance and consistency is foundational to the initial setup of compliance rules. It helps identify both the data inputs and business logic needed to calculate the numerator and denominator of each test. Depending on the governing body (e.g., state regulations), legal contract (e.g., investment management agreement), or internal strategy (e.g., strategic asset allocations), rules may use a different numerator basis such as GAAP or STAT book value, carry value, or market value. Additionally, each governing document may have unique defined terms that drive nuances for asset categories such as sector classifications and rating methodologies. In many cases, documentation is not comprehensive and leaves some level of subjectivity due to ambiguous terminology. For this reason, it is critical to implement an enterprise-wide interpretation of documentation to ensure compliance is measured consistent with the intention of the investment guideline.
Accelerate change with Managed Data Services
As is evident, data management for insurance companies is complex. It requires fit-for-purpose technology, a thoughtful business strategy, and disciplined governance to ensure data policy standards are adopted and enforced at an enterprise level. Many firms struggle to couple the business and technology elements due to the challenges described in this article along with a constantly evolving regulatory environment.
As such, insurance companies are seeking to outsource the data management and reporting function to firms that have the technology and subject matter expertise in this niche vertical of financial services. A managed data service will provide a modern data architecture that supports both sides of the balance sheet and offers flexibility to support the constantly evolving dynamics that are innate to insurance companies.
Compared to deploying in-house infrastructure to support data management and reporting, a managed service saves insurance companies time and money by offering a repeatable framework following industry best practices.
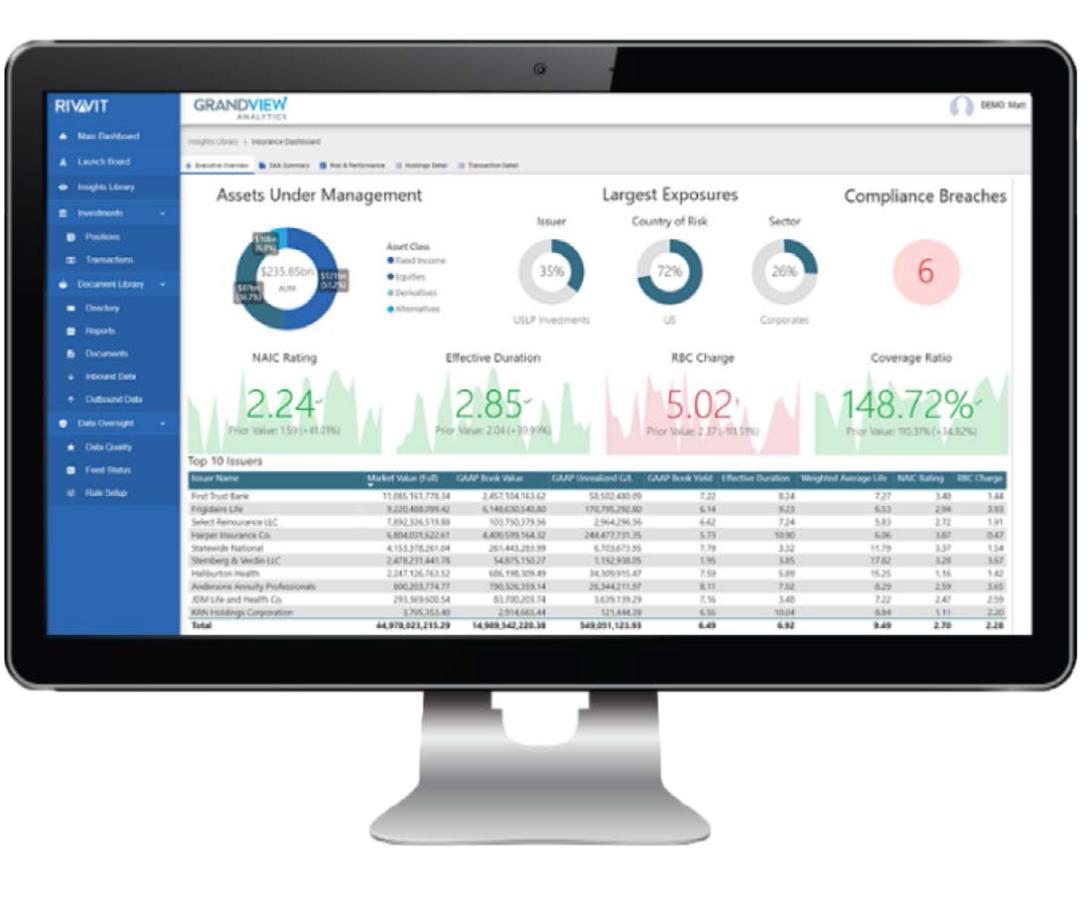
Grandview’s managed data platform, Rivvit, was designed to clean, govern and integrate data from multiple sources. Investment accounting data seamlessly integrates to portfolio management, compliance, risk, and other systems to provide decision makers with a holistic view of their book. Investment personnel can navigate custom dashboards, bringing together NAIC ratings, capital charges, risk exposures, book data, security analytics, compliance, and more.
About Grandview Analytics
Grandview Analytics is a technology consulting and data management software company serving the insurance industry. We provide strategic advisory, technology implementation, and data services to help asset managers and asset owners overcome technology, data management, and reporting challenges associated with evolving regulatory requirements and a shift toward more sophisticated asset allocation policies for complex asset classes and multi-manager strategies.
Our managed data and reporting platform, Rivvit, integrates disparate data to give insurers a single source of accurate, actionable, and reliable data. Contact our team for more information about how to consolidate your disparate data sources into a single version of the truth for your organization.
Read the E-Book Here