
Using machine learning for emerging market equity returns

Machine learning algorithms and models have large potential for investing in emerging stock markets, says quant researcher Laurens Swinkels.
- Linear and machine learning algorithms applied to emerging market stocks
- Five portfolios created based on the machine-predicted excess returns
- Machine models brought higher returns than traditional factor investing
Machine learning algorithms have surged in popularity among academics and practitioners as they seek to determine if they can enhance returns. Robeco’s quant team put this to the test by seeing what the application of such algorithms would mean for investing in emerging market equities1. The results were as useful as the machine learning models themselves.
We discovered that they excel at detecting financially material non-linear relationships between company characteristics – a feat that would be challenging for human researchers. We also found that using ensembling, or the ‘wisdom of the crowd’ for machine learning models, could increase expected returns net of trading costs by up to 2% per annum for equity investors.
The results came from analyzing more than 15,000 unique stocks from 32 countries between 1990 and 2021. We used 36 standard characteristics that can apply to both developed and emerging markets for the study, and opted not to introduce any new ones to highlight the added value that machine learning techniques can bring. This ensured that any additional performance gleaned wasn’t just the result of novel data but accrued to well-known factors such as low-risk, valuation, momentum and quality.
Different algorithms were then used to predict relative stock returns to their own country market index based on these factors. The least complex method assumes that each of the firm characteristics has a linear relationship to stocks’ outperformances.
Three machine learning methods were used to improve upon straightforward linear regression.
- Elastic net. This method aims to reduce the number of characteristics (36 in our case) by eliminating those with the lowest or no forecasting ability. It also minimizes the potential noise that may be present in a sample that could impair out-of-sample predictive performance. This method does not detect data-driven non-linear relationships or interaction effects.
- Tree-based methods. Random forests and gradient-boosted regression trees follow the idea of sequentially partitioning the underlying data into groups of firm characteristics – ‘growing’ a tree. New branches are created every time the data is separated. At each new branch, the characteristic that generates the biggest separation in the database is selected, with the tree growing as high as the researcher allows, ending in a leaf.
- Neural networks. These are flexible models that connect multiple layers. They consist of an input layer of firm characteristics and at least one hidden layer of activation functions. An output layer aggregates the hidden layers’ outcomes into a return prediction. When a model uses more than one hidden layer – ours uses up to five – it is sometimes referred to as a deep learning model.
With 1990 to 2001 as our initialization period, we used data from the first half for training and the second half for validation. We trained the models on our entire set of emerging market stock returns and refrained from developing country-specific models, because some evidence suggests these may lead to overfitting, which reduces out-of-sample performance.
We can then rank each of the 36 variables in order of their importance by evaluating the negative impact on prediction performance when the variable is left out and the rest of the model remains unchanged. We found that the models make similar choices regarding the most influential characteristics, with price to its 52-week high, idiosyncratic volatility, and turnover being the three most important.
Momentum and short-term reversal are also among the top 15, as well as the price/earnings ratio and profitability. This is information that is worth having. Detecting interaction effects between each of the 36 variables would be incredibly time-consuming and difficult for a human researcher, whereas a machine learning model is able to find these relationships quickly and systematically.
Investment performance
So they work in theory, but how do these interaction effects actually impact investment performance? For investors, it may be more relevant to back-test the signals coming from these models, allowing us to compare the risk and return of portfolios.
To test this, we formed five portfolios based on the machine-predicted excess returns of each stock relative to its country index. We then calculated the return in the next month, using market capitalization-based portfolio weights within each portfolio. Starting in our out-of-sample period from January 2002, we repeated this each month until December 2021, when our sample ends. The results can be seen in the chart below.
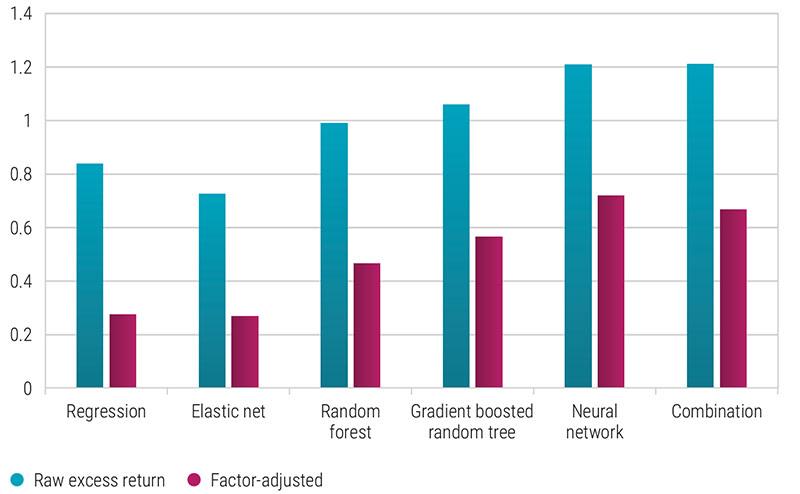
Source: Robeco, Hanauer and Kalsbach (2023) using data from January 2002 to December 2021
On average, the returns of the long/short portfolio derived from the two linear models, namely regression and elastic net, were around 0.8% per month. This is substantial and shows that conventional quantitative models are able to generate excess returns in emerging stock markets, confirmed by earlier studies on factor investing in emerging markets.
The random forest and gradient-boosted random tree methods generated higher returns of around 1.0% per month, while the neural networks method and a combination of all machine learning models delivered 1.2%. In short, linear models are good, but machine learning models are better.
Going back to basics
This does lead to the question of whether this is just a fancy way to pick up the conventional quantitative factors that have been employed in the investment industry for decades. Indeed, as the red bars show, a substantial part of the raw excess returns can be explained by these well-known factors.
On the one hand, this confirms that traditional factor investing can still predict future returns. On the other hand, it also shows that machine learning models give us greater, economically important insight that can bring even higher returns. The linear models show there is about 0.2% per month of alpha left to capture, which increases to 0.5% per month for the tree-based models, and 0.7% per month for the neural network method and the machine learning ensemble.
Hence, using machine learning signals is more profitable than conventional factor investing alone. Even accounting for transaction costs and short-selling constraints, we see that this type of forecast can lead to significant net outperformance over the market, and can be recommended to investors.
Footnote
1 See Hanauer and Kalsbach (2023), Machine learning and the cross-section of emerging market stock returns, Emerging Markets Review 55 (2023), 101022.
Sign Up Now for Full Access to Articles and Podcasts!
Unlock full access to our vast content library by registering as an institutional investor .
Create an accountAlready have an account ? Sign in